正规配资排名
正规配资排名
本文作者杨磊,目前在大模型初创公司阶跃星辰担任后训练算法工程师,其研究领域包括生成模型和语言模型后训练。在这之前,他曾在旷视科技担任了六年的计算机视觉算法工程师,从事三维视觉、数据合成等方向。他于2018年本科毕业于北京化工大学。
当前,主流的基础生成模型大概有五大类,分别是:Energy-BasedModels(Diffusion)、GAN、Autoregressive、VAE和Flow-BasedModels。
本项工作提出了一种全新的生成模型:离散分布网络(DiscreteDistributionNetworks),简称DDN。相关论文已发表于ICLR2025。
DDN采用一种简洁且独特的机制来建模目标分布:
1.在单次前向传播中,DDN会同时生成K个输出(而非单一输出)。
2.这些输出共同构成一个包含K个等权重(概率均为1/K)样本点的离散分布,这也是「离散分布网络」名称的由来。
3.训练目标是通过优化样本点的位置,使网络输出的离散分布尽可能逼近训练数据的真实分布。
每一类生成模型都有其独特的性质,DDN也不例外。本文将重点介绍DDN的三个特性:
零样本条件生成(Zero-ShotConditionalGeneration,ZSCG)
树状结构的一维离散潜变量(Tree-Structured1DDiscreteLatent)
完全的端到端可微分(FullyEnd-to-EndDifferentiable)

论文标题:《DiscreteDistributionNetworks》
离散分布网络原理
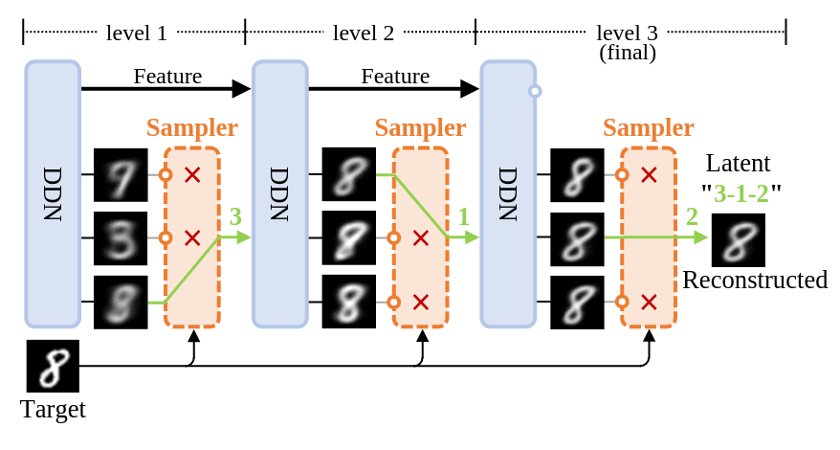
图1:DDN的重建过程示意图
首先,借助上图所示的DDN重建流程作为切入点来一窥其原理。与diffusion和GAN不同,它们无法重建数据,DDN能像VAE一样具有数据重建能力:先将数据映射为latent,再由latent生成与原始图像高度相似的重建图像。
上图展示了DDN重建target并获得其latent的过程。一般DDN内部包含多个层级结构,其层数为L,示意图里L=3。但先让我们把目光集中在最左侧的第一层。
离散分布:正如上文所言,DDN的核心思想在于让网络同时生成K个输出,从而表示「网络输出了一个离散分布」。因此每一层DDN都有K个outputs,即一次性输出K张不同的图像,示意图中K=3。每个output都代表了这个离散分布中的一个样本点,每个样本点的概率质量相等,均为1/K。
层次化生成:最终目标是让这个离散分布(K个outputs),和目标分布(训练集)越接近越好,显然,单靠第一层的K个outputs无法清晰地刻画整个MNIST数据集。第一层获得的K张图像更像是将MNIST聚为K类后得到的平均图像。因此,我们引入「层次化生成」设计以获得更加清晰的图像。
在第一层,橙色Sampler根据
距离从K个outputs中选出和重建target最相似的一张output。再把被选中的output图输入回网络,作为第二层DDN的condition。这样,第二层DDN就会基于condition(被选中的图)生成新的K张和target更相似的outputs。
接着,从第二层的outputs中继续选择出和target最相似的一张作为第三层的condition,并重复上述过程。随着层数增加,生成的图像和target会越来越相似,最终完成对target的重建。
Latent:这一路选下来,每一层被选中output的index就组成了target的latent(图中绿色部分「3-1-2」)。因此latent是一个长度为L,取值范围[1,K]的整数数组。
训练:DDN的训练过程和重建过程一样,只需额外在每一层中,对选中的output和target计算
loss取平均。
loss即可。总的loss就是对每一层
生成:在生成阶段,将Sampler替换为randomchoice即可:每一层从K个outputs中随机抽取一个作为下一层的condition。由于生成空间包含个样本点,复杂度随K和L指数级增长,随机采样的latent几乎不可能与训练集中的latent重合,因此可视为模型生成的新样本。
网络结构
将「重建过程示意图」进一步细化,就有下图(a)的网络结构图:
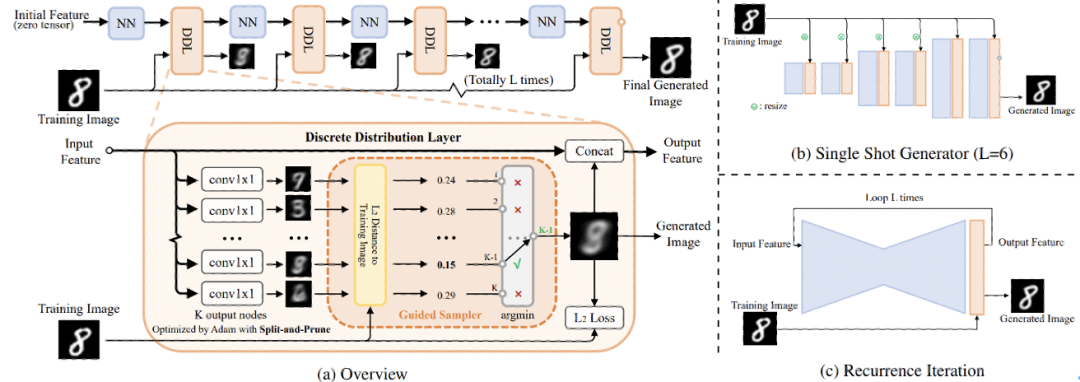
DDN网络结构示意图和支持的两种网络结构形式
在图(a)中,把生成相关的设计整合为DiscreteDistributionLayer(DDL),把仅提供基础计算的模块封装为了NNBlock,并重点展示训练时DDL内部的数据流。主要关注以下几点:
第一层DDN的输入为zerotensor,不需要任何condition;
DDL内部通过K个conv1x1来同时生成K个outputs;
然后,GuidedSampler从这些outputs中选出和trainingimage
距离最小的output;
被选中的output图像承担两项任务:[1].concat回feature中,作为下一层DDL的condition;[2].和trainingimage计算
loss。
右侧的(b)、(c)两图分别展示了DDN支持的两种网络结构形式:
(b)
SingleShotGenerator:类似GAN中生成器的decoder结构,但需要在网络中插入足够数量的DDL以确保生成空间
足够大。
(c)RecurrenceIteration:各层DDL共享相同参数,类似diffusion模型,需要做多次forward才能生成样本。
出于计算效率考虑,DDN默认采用具有coarse-to-fine特性的singleshotgenerator形式。
损失函数
DDN是由L层DDL组成,以第
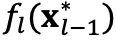
并从中找出和当前训练样本x最相似的样本及其index。最后,只在选中的样本上计算这一层DDL的loss
。公式及说明如下:
,生成K个新的样本
为例,输入上一层选中的样本
层DDL

其中,
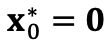
代表第一层DDL的输入为zerotensor。DDN的总loss就是每一层的
loss
取平均。
此外,本文还提出了Split-and-Prune优化算法来使得训练时每个节点被GT匹配上的概率均匀,都是1/K。
下图展示了DDN做二维概率密度估计的优化过程:
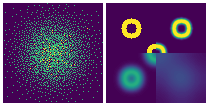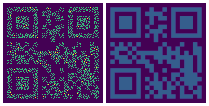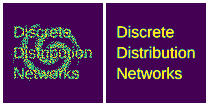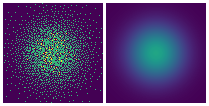
左:生成样本集;右:概率密度GT
实验与特性展示
随机采样效果展示

在人脸数据集上的随机采样效果
更通用的零样本条件生成
先描述一下「零样本条件生成」(Zero-ShotConditionalGeneration,ZSCG)这个任务:
首先,Unconditional地训练一个生成模型,即训练阶段,模型只见过图像,没有见过任何condition信号。
在生成阶段,用户会提供condition,比如textprompt、低分辨率图像、黑白图像。
任务目标:让已经unconditional训练好的生成模型能根据condition生成符合对应condition的图像。
因为在训练阶段,模型没见过任何的condition信号,所以叫Zero-ShotConditionalGeneration。

用UnconditionalDDN做零样本条件生成效果:DDN能在不需要梯度的情况下,使不同模态的Condition(比如textprompt加CLIP)来引导UnconditionaltrainedDDN做条件生成。黄色框圈起来部分就是用于参考的GT。SR代表超分辨率、ST代表StyleTransfer。
如上图所示,DDN支持丰富的零样本条件生成任务,其做法和图1中的DDN重建过程几乎一样。
具体而言,只需把图1中的target替换为对应的condition,并且,把采样逻辑调整为从每一层的多个outputs中选出最符合当前condition的那一个output作为当前层的输出。这样随着层数的增加,生成的output越来越符合condition。整个过程中不需要计算任何梯度,仅靠一个黑盒判别模型就能引导网络做零样本条件生成。DDN是第一个支持如此特性的生成模型。
换为更专业的术语描述便是:
>DDN是首个支持用纯粹判别模型引导采样过程的生成模型;
>某种意义上促进了生成模型和判别模型的大一统。
这也意味着用户能够通过DDN高效地对整个分布空间进行筛选和操作。这个性质非常有趣,可玩性很高,个人感觉「零样本条件生成」将会得到广泛的应用。
ConditionalTraining
训练conditionalDDN非常简单,只需要把condition或者condition的特征直接输入网络中,网络便自动学会了P(X|Y)。
此外,conditionalDDN也可以和ZSCG结合以增强生成过程的可控性,下图的第四/五列就展示了以其它图像为ZSCG引导的情况下conditionalDDN的生成效果。

Conditional-DDNs做上色和边缘转RGB任务。第四、五列展示了以其它图像为引导的情况下,零样本条件生成的效果,生成的图像会在保证符合condition的情况下尽可能靠近guided图像的色调。
端到端可微分
DDN生成的样本对产生该样本的计算图完全可微,使用标准链式法则就能对所有参数做端到端优化。这种梯度全链路畅通的性质,体现在了两个方面:
1.DDN有个一脉相承的主干feature,梯度能沿着主干feature高效反传。而diffusion在传递梯度时,需多次将梯度转换到带噪声的样本空间进行反传。
2.DDN的采样过程不会阻断梯度,意味着网络中间生成的outputs也是完全可微的,不需要近似操作,也不会引入噪声。
理论上,在利用判别模型做fine-tuning的场景或着强化学习任务中,使用DDN作为生成模型能更高效地fine-tuning。
独特的一维离散latent
DDN天然具有一维的离散latent。由于每一层outputs都conditionon前面所有的results,所以其latentspace是一个树状结构。树的度为K,层数为L,每一个叶子节点都对应一个DDN的采样结果。
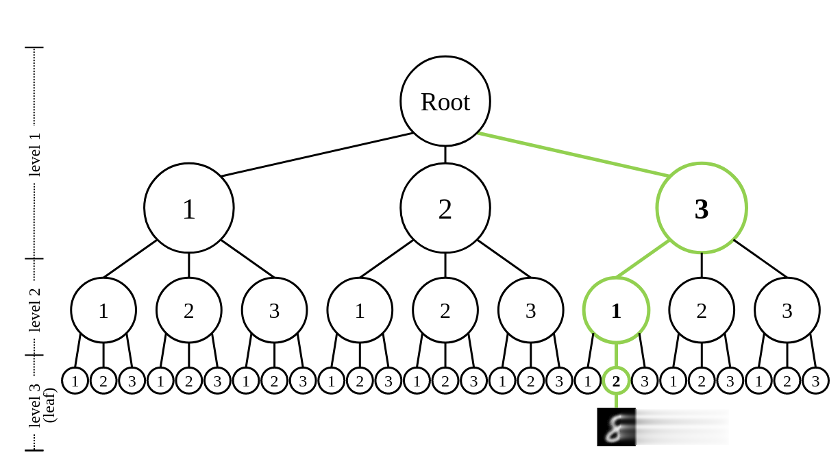
DDN的latent空间为树状结构,绿色路径展示了图1中的target所对应的latent
DDN具有较强的数据压缩能力(有损压缩)。DDN的latent是一列整数(listofints),属于高度压缩的离散表征。一个DDNlatent有
个bits的信息量,以人脸图像实验默认的K=512,L=128为例,一个样本可以被压缩到1152bits。
Latent可视化
为了可视化latent的结构,我们在MNIST上训练了一个outputlevel层数L=3,每一层outputnodes数目K=8的DDN,并以递归九宫格的形式来展示其latent的树形结构。九宫格的中心格子就是condition,即上一层被采样到的output,相邻的8个格子都代表基于中心格子为condition生成的8个新outputs。
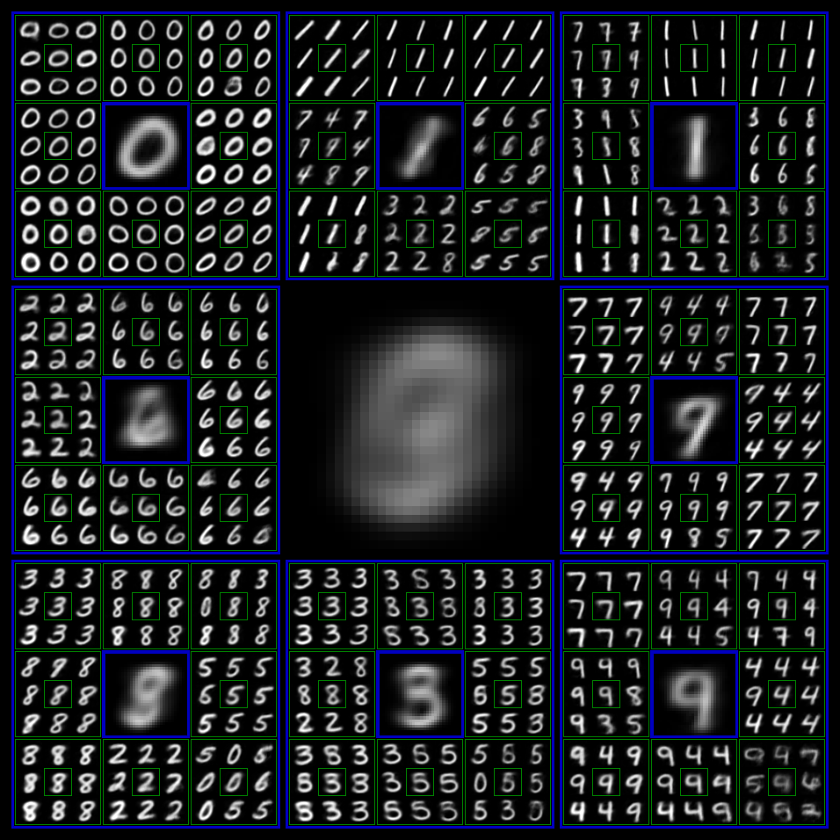
HierarchicalGenerationVisualizationofDDN
未来可能的研究方向
通过调参工作、探索实验、理论分析以改进DDN自身,Scalingup到ImageNet级别,打造出能实际使用、以零样本条件生成为特色的生成模型。
把DDN应用在生成空间不大的领域,例如图像上色、图像去噪。又或者RobotLearning领域的DiffusionPolicy。
把DDN应用在非生成类任务上,比如DDN天然支持无监督聚类,或者将其特殊的latent应用在数据压缩、相似性检索等领域。
用DDN的设计思想来改进现有生成模型,或者和其它生成模型相结合,做到优势互补。
将DDN应用在LLM领域正规配资排名,做序列建模任务。
大智慧配资提示:文章来自网络,不代表本站观点。



沪深京指数
热点资讯